
目录
- 1.6 VGG & GoogleNet
- 1.6.1 VGGNet
- 1.6.2 GoogleNet
- 1.6.2.1 Bottleneck Layer
- 1.6.2.2 Inception 模块
- 1.6.2.3 Inception-v1 网络架构
1.6 VGG & GoogleNet
在前文中,我们提到,通过对 CNN 网络架构进行可视化研究,我们发现网络层次增多会带来一定的性能提升,为了继续探索 CNN 网络架构在深度层面的性能问题,在 ILSVRC2014 中,牛津大学团队提出的 VGG 网络架构和 Google 团队提出的 GoogleNet 分别获得图像分类任务的亚军和冠军,其识别误差率远低于 AlexNet 和 ZFNet,如下图所示:
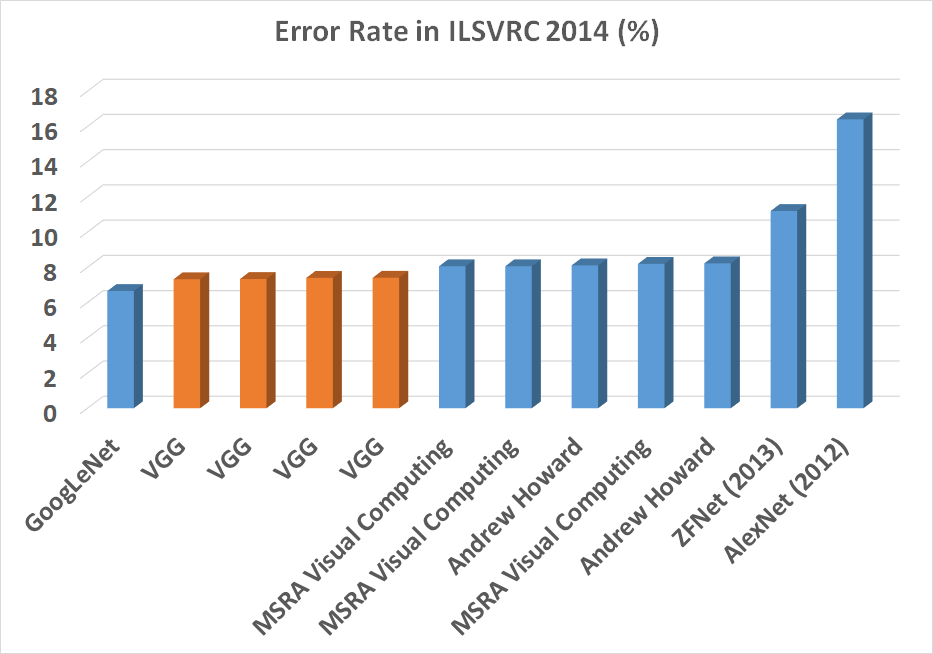 【图 1】
【图 1】
在本章节,我们讲解 VGG 网络是如何在深度层次上进一步优化网络架构的。
1.6.1 VGGNet
在 VGG 中,我们几乎只使用 3 × 3 3\times 3 3×3 大小的卷积核(只有一个网络配置中使用了 1 × 1 1\times 1 1×1 卷积核), 3 × 3 3\times 3 3×3 是具有捕获方向感(上下左右中)的最小卷积核,在之前的 CNN 架构中,一般会采用卷积核+池化层的组合方式,而在该网络架构上,我们可以发现并不是所有的卷积层后面都会加入池化层。这么做的主要原因是多层连续的小卷积核实际等价于一个大卷积核的作用。
 【图2】
【图2】
例如上图,两层连续的 3 × 3 3\times 3 3×3 卷积核其实际等价于一层 5 × 5 5\times 5 5×5 卷积核的作用。而连续 3 层的 3 × 3 3\times 3 3×3 卷积核相当于一个 7 × 7 7\times 7 7×7 卷积核的作用。既然它们的作用等价,为何还要如此?
首先,我们更多的卷积层就可以从中引入更多的 ReLU 非线性激活函数,增加网络的模型容量,使得网络有能力解决更复杂的模式;其次从数学计算角度而言,可以显著降低参数量,避免过拟合,因此也可以理解为一种正则化手段。
举例而言,假设输入和输出空间通道数均为
C
C
C,则一层
11
×
11
11\times 11
11×11 的卷积核参数量为
11
×
11
C
2
=
121
C
2
11\times11 C^2=121C^2
11×11C2=121C2,而具有等价作用的连续 5 层
3
×
3
3\times 3
3×3 卷积核的参数量为
5
×
(
3
×
3
)
C
2
=
45
C
2
5\times(3\times3)C^2=45C^2
5×(3×3)C2=45C2,减少了 63% 的参数量。
 【图 3】
【图 3】
在网络架构设计方面,VGG 实现了 6 种不同的网络配置,所有网络的最后由三个连续的全连接组成,前面由不同层次的卷积层和池化层组成。A 网络架构 VGG-11 是基准网络架构, A-LRN 是在 A 的基础上加入了 LRN,B 架构在 A 的基础上引入更多的卷积层,C 架构则引入了 1 × 1 1\times 1 1×1 卷积层,D架构将 C 中所有的 1 × 1 1\times 1 1×1 替换回 3 × 3 3\times 3 3×3,即被人所熟知的 VGG-16 架构,而 E 则进一步引入更多的网络层,即 VGG-19 架构。
1 × 1 1\times 1 1×1 的架构并不会降低网络参数量,表面上看并没有对原架构造成任何影响,但是引入的 1 × 1 1\times 1 1×1 卷积层也可以带来非线性激活。实际上, 1 × 1 1\times 1 1×1 的卷积核重在不同通道间的数据融合,因为卷积操作是基于输入空间的所有通道执行的,这一点的思想实际来自于 “Network in Network”1
通过观察网络架构中不同层的通道数可以发现,随着网络深度的加深,网络宽度(通道数)成倍增加,这种网络架构也对被后来网络发展所采用。其直观化解释为,网络的低层主要检测简单的纹理、颜色、边缘等简单特征,因此少量的卷积核便可以完成,而随着深度的加深,网络需要组合简单特征抽取更为复杂的特征形式,因此需要更多的卷积核来完成,当然这只是一种形式化理解。
 【图 4】
【图 4】
实验证明,引入 LRN 并没有带来性能的提升(甚至降低了),反而会消耗更多的内存及训练时间,因此,此后的主流网络架构受其影响均不再使用 LRN 技术,转而使用 BN 等正则化层技术。VGG-13(B架构)的误差率在 9.9%,说明引入新的卷积层可以带来性能的提升,VGG-16(Conv 1)因为引入了 1 × 1 1\times 1 1×1 的卷积核,其误差率进一步降低,证明了额外引入的三层 1 × 1 1\times 1 1×1 卷积核的确可以带来分类性能上的提升,且该技术在 GoogleNet 以及后来的 ResNet 网络中被大量使用。VGG-16 由于引入更多的卷积层,其性能进一步得到提升(8.8%),然而在 VGG-19 中,其性能没有得到进一步提升(9.0%)这说明,单纯的引入更多的卷积层,其性能不会被无限提高。目前提到的 VGG 网络主要有 VGG-16 和 VGG-19 两种架构。
VGG 作者随后采用多尺度训练、多尺度测试、密集测试以及模型消融实验,最终可以将误差率降低到 6.8%。
1.6.2 GoogleNet
GoogleNet,也称为 Inception-V1, 相比较之前的 LeNet-5、AlexNet、VGG 等网络架构,有了很大的不同,其核心技术主要是大量采用 1 × 1 1\times 1 1×1 卷积核,以及 Inception 模块的构建。其中 1 × 1 1\times 1 1×1 的主要思想主要来自于 “Network in network(NIN)”1。而网络之所以命名为 Inception,主要是受 NIN 影响及电影 Inception(盗梦空间)影视截屏表情包影响。
 【图 5】
【图 5】
1.6.2.1 Bottleneck Layer
在 VGG 中,不仅网络的深度加深,且网络的宽度也不断加宽,这使得网络参数急剧性增长,参数增多不仅需要更多的训练数据及训练时间,而且存在过拟合的风险,因此这是一种投入与产出不成比例的做法,也限制了网络的规模,因此 1 × 1 1\times 1 1×1 卷积核在 GoogleNet 网络中被大量使用,其主要目的就是突破计算瓶颈,因此也被称为 “Bottleneck Layer”,这不仅允许我们在深度层面加深,也允许在宽度的增加且没有明显的性能损失。
 【图 6】
【图 6】
例如在上图中,当我们仅使用 5 × 5 5\times 5 5×5 卷积核时,其计算量为 14 × 14 × 5 × 5 × 480 × 48 = 112.9 M 14\times 14 \times 5\times 5\times 480\times 48=112.9M 14×14×5×5×480×48=112.9M,当我们先使用 16 个 1 × 1 1\times 1 1×1 卷积核将维度降低到 16 后再次运用 5 × 5 5\times 5 5×5 卷积核时,其参数量为 14 × 14 × 1 × 1 × 480 × 16 + 14 × 14 × 5 × 5 × 16 × 48 = 1.5 M + 3.8 M = 5.3 M 14\times 14\times 1\times 1\times 480\times 16 + 14\times 14\times 5\times 5\times 16\times 48=1.5M+3.8M=5.3M 14×14×1×1×480×16+14×14×5×5×16×48=1.5M+3.8M=5.3M,将其计算量降低了 112.9M,如下图所示。此处的降维操作实际上是通过非线性映射将数据从高维映射到低维,不同于 PCA 等线性降维方式。
 【图 7】
【图 7】
1.6.2.2 Inception 模块
在此之前,我们认为提高深度网络性能最直接的方式就是增加它们的深度或宽度,在拥有大量标注的训练集下,该方法往往更易实现且安全有效。然而这种做法存在两个致命缺陷:
- 更大规模的网络往往意味着更多的网络参数,这就需要更多的标注数据集,而标注数据集的获取目前依然需要高昂的人工成本,且存在过拟合风险;
- 第二个是计算成本的增加,这需要更多的计算资源及训练时间
为了解决这两个问题,一个基本的方式就是将密集的全连接层替换为稀疏性连接,甚至卷积操作中的局部密集连接也可以被替换为稀疏连接,然而目前的计算机硬件对稀疏矩阵的计算性能远不如密集矩阵。因此 Inception 架构的主要想法是用密集计算组件近似卷积网络的最优稀疏结构。Inception 模块的基本组成思路是用不同大小的卷积核及池化操作运用到同一特征输入空间,然后将不同的输出特征图聚合在一起,如下图所示。
 【图 8】
【图 8】
结合我们上文的 1 × 1 1\times 1 1×1 卷积核,我们进一步把该卷积核引入到 3 × 3 3\times 3 3×3、 5 × 5 5\times 5 5×5 及池化操作中,如下图所示:
 【图 9】
【图 9】
直观上理解,此处我们不再严格限制卷积核的大小以及应该进行卷积或池化操作,而是由网络并行在不同尺度的卷积核上进行学习,以实现近似密集计算组件的稀疏连接结构。
1.6.2.3 Inception-v1 网络架构
网络整体架构设计如下表所示:
 【图 10】
【图 10】
其中 “# 3 × 3 3\times 3 3×3 reduce” 和 “# 5 × 5 5\times 5 5×5 reduce” 表示在 3 × 3 3\times 3 3×3 和 5 × 5 5\times 5 5×5 卷积核之前使用的 1 × 1 1\times 1 1×1 卷积核的数量。“pool proj” 表示在 Inception 模块内池化后应用的 1 × 1 1\times 1 1×1 卷积核数量。
另外网络最后将连接层替换为全局平均池化层,并提高了约 0.6% 的准确率,然而 Dropout 正则化层仍必不可少。
全局平均池化:
全连接层或全局平均池化操作的目的都是将卷积操作输出特征图展开,以便于网络最终的输出层连接,但是全连接层需要引入大量的计算参数,
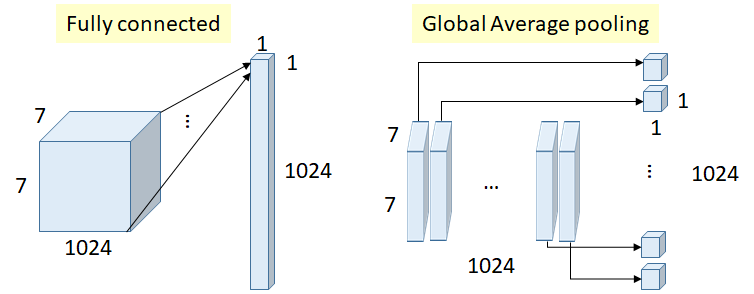 【图 8】
【图 8】
如上图所示,如果采用全连接操作,则参数量为 7 × 7 × 1024 × 1024 = 51.3 M 7\times 7\times 1024\times 1024=51.3M 7×7×1024×1024=51.3M,该参数量是巨大的。而全局平均池化是基于每一个通道特征图( 7 × 7 7\times 7 7×7)求平均值,该过程没有引入任何参数。
另外网络在训练阶段还加入一些辅助分类器层,作者声称具有一定的正则化作用,且缓解了梯度消失问题,该策略在测试和推理阶段没有被使用。
Lin, M., Chen, Q., and Yan, S. Network in network. In Proc. ICLR, 2014. ↩︎ ↩︎





